On Building Language Machines and Snakes Eating Their Tails
Taco happy hour, UX Drinks, Tiki time by the Chicago River. Elephant and Castle on a Thursday. The office kitchen at whatever hour it was when someone finally broke out the good coffee and a whiteboard marker and started drawing trees.

Parse trees. NP, VP, NP. Noun phrase, verb phrase, noun phrase, recursively, all the way down until the structure either resolved into something you could express in code or you ran out of wall. This was Chicago in the early 2010s. The third AI summer was just starting to get warm, though I was just learning the history of artificial intelligence then (while inventing it, too).
A Gartner Magic Quadrant for our core technology — natural language generation — didn't exist yet because the niche barely existed. We were one of maybe five companies that we knew of in the world doing what we were doing, and the fact that we were all doing it slightly differently was less a sign of healthy competition than of everyone genuinely guessing with what capabilities we had at the time.
What we were doing, at Narrative Science, was teaching machines to tell stories. Take structured data to produce a box score summary, an automated Forbes Earnings Preview, or an overview of sales performance based on dashboard data. Ideally, with stories that no one immediately recognized as machine-written. The platform was called Quill (and subsequently Quill 1, 2, and 3).
The founders were Kris Hammond and Larry Birnbaum, both from Northwestern University. In 2012, Kris told a Wired journalist that a computer would win a Pulitzer Prize within five years, and that 90% of journalism would be machine-written within fifteen (pretty much true). The kind of prediction that sounds absurd until you realize in hindsight we were only wrong about the timeline.
I was in my mid-twenties, Technical Product Manager for Platform and UX, the first product hire at the nascent startup. My first day in the office I wired my own ethernet cable to my desk. Classic. The fun of naming your agile team after Final Fantasy characters was still novel. We thought we were clever calling our domain-specific language qython (a mashup of Quill and Python). We presented machine-generated sentences at Sprint Reviews with the gravity of a moon landing: "There are 9 transactions in total. All Parts LLC received 4 transactions." Everyone nodded seriously. The fact that we needed to invent a language to describe the rules of language should have told us something.

It took me years to understand exactly what. In the meantime, my phone piled up with Sprint Retro images of our whiteboards. I was already a sentimental archivist for our team.
Aug 21, 2014, 3:17 PM: Did weird things with data in Quill. Data cannon is still terrible. Quill releases are brittle. Legacy config structures are bad. Being on-call repeatedly sucks.

Even if we were off on our timeline and slightly ahead, it was a formidable time for my understanding of technology and product strategy. Sweating the details alongside bright and slightly obsessive peers, working with some of the largest companies and investors (which would've rattled me at the time had I known the magnitude, bless naiveté).
Having leadership be a part of the United Nations Institute for Disarmament Research in the early aughts, bringing back principled research to our hungry minded teams, ex-linguists and physicists trying their best to codify communication in reusable bits and bytes. I debugged prototype Airbus alerts summarizing steps of flight manuals, worked with the first versions of the Twitter firehose, flew to Virginia to gather requirements from the US Intelligence Community, and trained Big 5 consultants how to use our (way too complicated, truly) platform. An irreplaceable journey in my career.
Later, as Director, I tripled the engineering, product and UX teams to keep up with the wide span of use cases and experimental forays into integrations (and porting AWS deployments to bare metal on-premise). I'll tell you about flying unencrypted DVDs of our uncompiled software to DC and trying to walk Federal employees through installation guides that I blindly debugged with them (due to my lack of clearance lol) some other time.
The Argument Woven into Our Patents
Language isn't data with punctuation. A sentence carries semantic content (what is being said), pragmatic intent (why it's being said, to whom), syntactic structure (how the pieces relate), and lexical choice (which specific words, from all equivalent options, actually land). These aren't separate modules you can solve sequentially. They're entangled — the choice of a word affects the structure, the structure shapes the intent, the intent constrains what content gets selected in the first place.
The Narrative Science patent family, taken across roughly a decade of filings, traces an arc through that entanglement that reads, in retrospect, like a single slow argument about the nature of meaning.
The earliest work is a hand-built library of "angles" — abstract narrative structures like come-from-behind victory, heroic individual performance, rout — matched against incoming data and traversed to produce language. Every story shape manually defined. Labor-intensive in a way that only becomes visible when you enter a new domain and realize you have to rebuild the whole structure from scratch.
Phases → get data, parse, map, validate. Transform into Quill's needs. Customer by customer. Domain by domain. The gap between data and meaning, restated fresh for every client (a gift and a curse, this ended up being prohibitive to scale).

The middle-era patents introduce the ontology as a living object that grows concurrently with communication goals — the claim being that domain knowledge and expressive structure aren't separable. The system splits into two AI components: one deciding what to say, one deciding how to say it, divided at the seam where meaning becomes words. In the product, this looked like a mapping interface: `salesperson_name` → knowledge base concept "salesperson" → expression → description.
Every column in a dataset becoming a node in a semantic graph. Every node requiring a human to decide what it meant. Iterating through writing these patents was painful, but the team had working examples of production use. It wasn't theoretical to us because we were merely explaining how our concepts came to life. Explaining what we were building was easy (but tedious in patent-ese). The worst part for me was accidentally putting some of my early diagram sketches into an overflowing box during one of our office celebrations thinking it was going into our 10 year time machine - only for our office building to accidentally throw the entire box out during their nightly cleanup. Turn Back Time, Please!
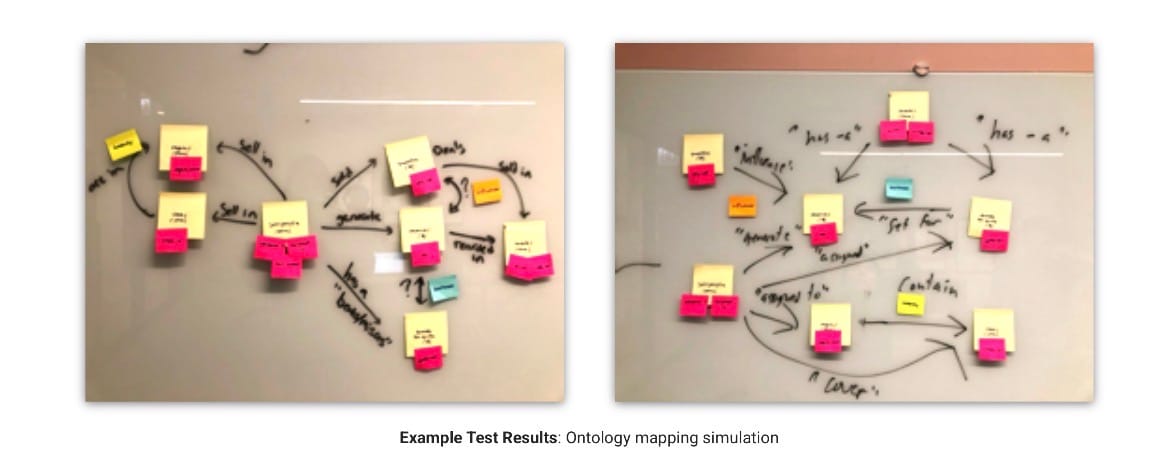
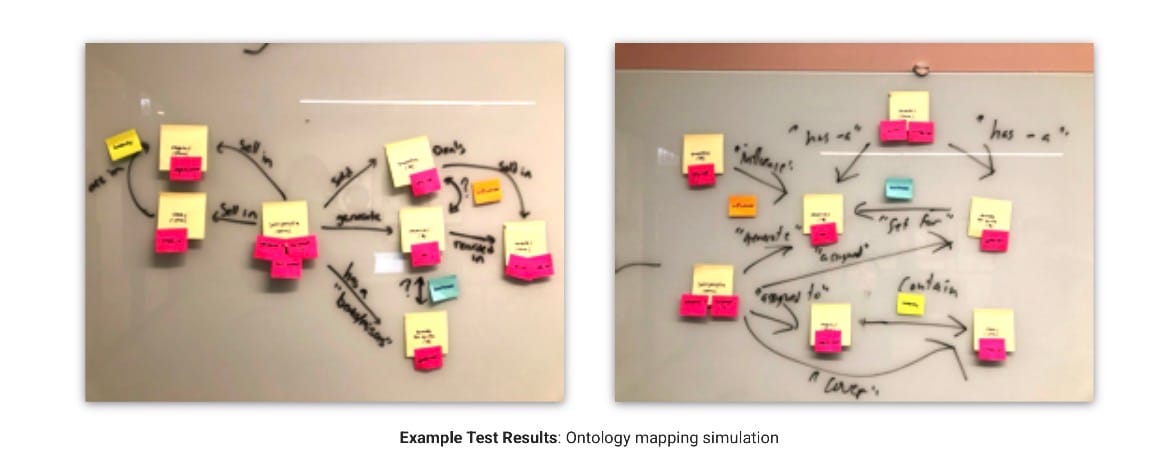
The late patents close the loop: the system reads human-written narratives to train the generation component, extracting stylistic patterns and mapping them back onto the ontology. It learns to write by reading. To generate language, it must first comprehend it. To comprehend well enough to learn, it needs exactly the internal model that generation requires. Natural language processing to structured data to natural language generation and back again.
The snake is eating its tail in the architecture diagram. Not as a design flaw. As the structure of the problem itself.
How Children Do It for Free
Here's what gets obscured by how effortlessly language acquisition happens: it is not the learning of rules followed by the application of those rules. The rules emerge — through something much more like what we were building by hand, just implemented in biological wetware at a scale no engineering team could approach.
A child builds proto-ontologies through pointing and labeling. That is a dog. That is hot. Mama goes bye-bye. Not vocabulary lessons — the establishment of semantic primitives (entities, properties, states, events) and relationships between them. Comprehension and production develop in tandem, not sequentially. The generative capacity and the comprehension capacity are the same underlying representational structure accessed from opposite directions. Understanding is traversing meaning from surface down to semantic content. Generating is traversing the same structure from semantic content up to surface. Same map. Two directions of travel.
This is what we were building at Narrative Science. The ontology was the map. We needed the "what to say" AI and the "how to say it" AI both, because they are not two problems. They are one problem with two entry points.
Scale Changes Everything Except the Shape
When the transformer architecture arrived in 2017, it didn't solve the ontology problem. It made the ontology learnable at scale. No hand-crafted domain knowledge, no explicit communication goals, just immersion in hundreds of billions of sentences with prediction as the learning signal. What emerged was something functionally equivalent to an ontology distributed across billions of learned parameters: entities, relationships, properties, semantic fields, pragmatic registers. The structure of meaning, implicit in the weights.
The transformer learned what we were building by hand using the same method a child uses. The map is a byproduct of getting good at navigation. What we were doing at Narrative Science was drawing that map by hand for specific domains, one at a time. The shape of the problem was always the same. We just didn't have a big enough snake.
In December 2021, Salesforce acquired Narrative Science, rolling it into Tableau. The patents ended up inside Salesforce, living in enterprise analytics infrastructure used by millions of people who likely have no idea a small, Chicago-based company spent years drawing parse trees to figure out what it takes to make data legible across different human minds. That's what it looks like when an idea gets absorbed into the world.
Pretty soon, enterprise business intelligence was used to automated summaries by default. And we were the twenty-somethings that made it happen.

What You Do With It Next
Years later I found myself on a panel in Chicago, next to some of the same people from those whiteboard evenings (fueled by design sessions feat. Meshuggah, Dave Brubeck, Muramasa, RL Grime - what a time!). We were talking enterprise AI adoption. The problem had shifted registers without changing shape. In the NLG years: how do you make meaning legible to a machine? At the enterprise level: how do you make AI's output legible to an organization full of people who think differently? Same question. Different substrate.

What I've done with that understanding since comes in two forms. The first is through building the game The Glass Garden where I used AI-assisted coding to experience trade-offs agentic systems make felt rather than explained. The Amber Lab mechanic, where you sacrifice text-based memories to make agents smarter and watch your own archive shrink, is RAG made visceral. The Reflection Chamber, where controlling agent behavior costs hull integrity, is alignment made expensive. Game mechanics are arguments, and the argument here is the same one the patents were making: comprehension and generation are one loop.
The second is a distributed system — what I've written about elsewhere as the homestead agentic web. Two people (two families and more nodes forthcoming), different cognitive styles, using AI as translation infrastructure between us. The shared context layer is the ontology. The communication goal isn't a financial report. It's a life, built deliberately.
In both cases, what I carried forward from those Chicago evenings is the same conviction. That meaning isn't given. It's built. Slowly. Collaboratively. Node by node, one pointed-at dog at a time.
This essay is part of Deep Familiar Ground — a series on distributed nodes, earned trust, and the quiet work of building systems that don't fall apart when you're not watching.